

網站上線,只能全站被收錄嗎?
無論是自己架站,亦或是協助客戶網站問題排除時,是不是總會遇過『為什麼我的網站上線這麼久,卻都沒有好的排名?』這類相關疑惑呢?但在所謂『好的排名』這前提大方向,你是否該先注意『我的網站有沒有被搜尋引擎收錄了』這件事呢?如果你的網站在Google或Bing上連收錄都沒有,『排名』這件事就變成是空想了,不是嗎?
那麼你是否曾經想過,Google或Bing等搜尋引擎,很盡責的將線上運作的網站抓到搜尋引擎清單內做索引,並提供給使用者尋找各種資訊時,什麼情況下會被拒絕索引,亦或者若我的網站有些東西不想被搜尋到或”暫時”不想被搜尋到,那有沒有什麼辦法可以阻止搜尋引擎呢?
是的,方法是有的,就讓我們awoo團隊替你娓娓道來!
- 是網頁內作法,使用所謂的meta標籤阻擋,但壞處是必須每一個網頁都需獨立設置使用。
- 而第二種方式,則是可以針對整個網站做規範的限制,這就是本次要講的主題:Robots.txt。
搜尋引擎到底對網站做了哪些事?
搜尋引擎的運作原理是什麼呢?
簡單來說,搜尋引擎會先針對網站做Crawl(檢索)與Index(索引),然後將網站資訊收錄,根據各家演算法計算後做出排序,提供搜尋結果給使用者查詢。(當然其中還有很複雜的各種計分方式,但這邊就不細談了)
Robots.txt就是這時派上用場,主要行為就是在搜尋引擎檢索網站時,告訴它網站哪些內容可以被檢索,哪些內容可以不用被檢索。
不過這邊有一點很重要需說明,雖然 Google 不會對 Robots.txt 所封鎖的內容進行檢索或建立索引,但若我們透過網路上其他網頁的連結發現封鎖的網址,仍然會建立這些網址的索引。因此,網頁網址以及其他可能的公開資訊 (例如網頁連結中的錨點文字) 仍然會出現在 Google 搜尋結果中。如要完全避免這種情形,建議您使用密碼保護伺服器上的檔案,或是使用 noindex 中繼標記或回應標頭 (或完全移除網頁)。
更多禁止網頁被收錄的方法亦可參考我們awoo先前的文章:使用noindex”等4種方式禁止特定網頁被收錄,提升網站整體seo品質
若想近一步了解檢索與索引,可參考Google提供的檢索與建立索引
為何有網頁不想被收錄的可能?
可能有人好奇,什麼時候或有上述狀況發生呢?網站都完成了,就是希望他可以被蒐錄跟上線不是嗎?
這狀況比較可能出現的情境與受眾比較常見的可能有這些
- 尚未完成的網站但需上線實測的網站:有些網站可能上線是為了協作測試,亦或者用工具做壓力測試,但測試階段又不想被搜尋引擎檢索內容,這時就可以用到Robots.txt做排除了。(但在這建議搭配noindex使用,效果最佳)
- 網站管理者後台:有許多CMS(內容管理系統,如:Wordpress)與自行架設的網站會提供管理者後台登入的入口,這些通常是為了網站維護與管理而設置的入口,沒有被檢索的必要。
- 特定資料夾內檔案:網站希望搜尋引擎檢索的,往往是有內容的資訊,許多後台使用的檔案,就會以資料夾形式或正規字元方式(正規字元使用方式可見此篇後續的進階使用說明)做排除檢索的動作。
Robots.txt 怎麼做?
只要有文字編輯器,都可以完成,比較需要注意的是必須使用UTF-8 編碼的純文字檔才可以,如果使用的字元編碼會造成使用到非 UTF-8 的子集的字元,這種情況可能會導致檔案內容的剖析不正確。詳細說明規範可參考Google的Robots.txt 規範中的檔案格式說明。
比較推薦的第三方編輯器也可以參考:
Robots.txt 怎麼用?
基本會用的幾個參數分別如下:
- User-agent => 定義下述規則對哪些搜尋引擎生效,即是對象。
- Disallow => 指定哪些目錄或檔案類型不想被檢索,需指名路徑,否則將會被忽略。
- Allow => 指定哪些目錄或檔案類型可能被檢索,需指名路徑,否則將會被忽略。
- Sitemap => 指定網站內的sitemap檔案放置位置,需使用絕對路徑。
延伸閱讀:sitemap.xml網站地圖是什麼?從工具/產生器/程式製作到進行提交教學
使用範例參考
就算知道參數,但往往看著參數但卻無從下手的狀況也很頻繁,所以從範例下手,是最容易理解且好入門的方法。
以下是幾種常見及可能使用到的方式:
基本應用
- 允許所有搜尋引擎檢索所有內容(通常建議使用)
User-agent: *
Disallow: - 拒絕所有搜尋引擎檢索所有內容(正式環境請避免使用)
User-agent: *
Disallow: / - 拒絕所有搜尋引擎檢索/members/底下所有內容。
User-agent: *
Disallow: /members/ - 拒絕Google搜圖的爬蟲檢索/images/底下所有內容。
User-agent: Googlebot-image
Disallow:/images/
進階應用
- [萬用字元]拒絕所有搜尋引擎檢索網站內png為副檔名的圖檔。
User-agent: *
Disallow: *.png$ - [萬用字元]拒絕Bing搜尋引擎檢索網站內/wp-admin目錄底下所有內容及網站內開頭為test的所有檔名。
User-agent: bingbot
Disallow: /wp-admin/
Disallow: ^test*
Robots.txt測試方式
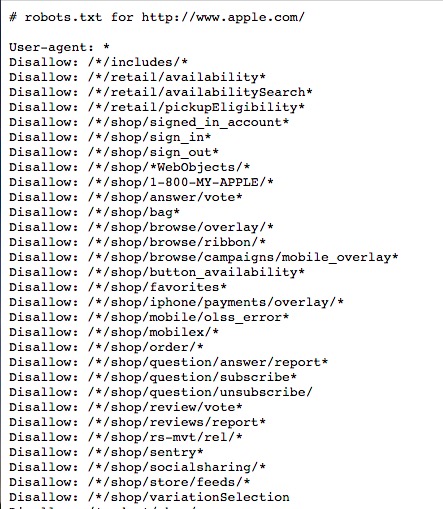
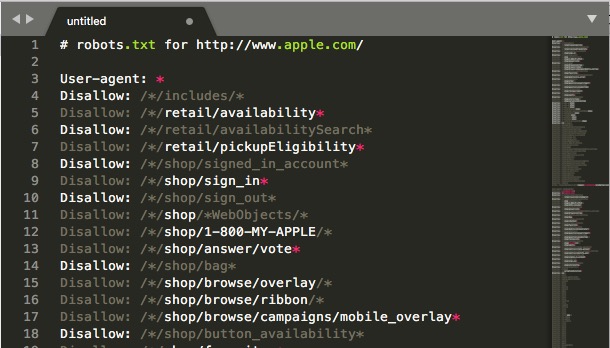
如果要驗證自己的網站有無Robots.txt,最簡單的方式是直接在網站根目錄下輸入robotx.txt做測試,檢驗是否存在。
例:https://www.apple.com/robots.txt
而若不知道目前robots.txt語法是否正確,也可以借助Google Search Console工具來做測試。

在Search Console內,左側的『檢索』內,點選『robots.txt 測試工具』,可在裡頭測試當前robots.txt檔案是否有問題,也可直接查看即時robots.txt的檔案內容。
若是還是擔心自己的某些網址會被robots.txt設置封鎖,也可用工具下方的提交網址方式做測試。

同樣的也可以在Bing Webmaster內,測試是否有被robots.txt檔案阻擋的檔案項目。

Robots.txt小細節
Robots.txt的規範中也有著各種細節跟設置,雖然非組成的必要元素,但若懂得如何應用,對設置Robots.txt相信會更有心得:)
- Sitemap在Robots.txt內是屬於non-group 紀錄,即是位置並沒有限制,並不會因為User-agent或Disallow所影響,可放置於任何位置。
User-agent: bingbot
Disallow: /wp-admin/
Disallow: ^test*
Sitemap: http://www.abc.com/sitemap.xml
- Crawl-delay參數可指定搜尋引擎爬蟲來訪的間隔時間(單位為秒),下述例子即表示:告訴爬蟲,再次來訪的最短時間間隔為20秒。
User-agent: *
Crawl-deslay: 20
注意:百度公開表示不支援此語法
- 目前大型的搜尋引擎,如:Google、Ask、Bing、Yahoo 均支援 Robotx.txt內的Sitemap指向。
4.Robots.txt的檔案命名方式必須為小寫字母(robots.txt),若命名為Robots.txt或robots.TXT等皆為不正確的命名方式,將會被搜索引擎的爬蟲忽略。
- Robot.txt檔案只能放在網站的根目錄底下,若非根目錄則不會被發現。
詳細資訊也可以在Google的Robots.txt 規範確認其他使用方式與項目類別。
結論,所以Robots.txt到底重不重要?
Robots.txt,他真的很重要嗎?我想,答案不是絕對的,但肯定的是『如果設置錯了,影響層面是非常深的』。在一般正常網站運作下,沒有額外設置Robots.txt檔,頂多影響會是『不太好』;但若有不少測試頁面或尚未完成版面,忘了設置使用Robots.txt做排除內,那影響不意外的肯定『比較大』;而繞回最一開始討論的內容,若你的網站準備好了也上線了,你的目標是希望有好的排名時,這時若錯誤使用Robots.txt阻擋搜尋引擎來做索引,那就絕對是『非常不好』。
在這個SEO一直反覆強調內容為王的時代,資訊架構的影響真的可大可小,但不可否認的是,若架構的初期的第一步就走錯了,那影響絕對是很深遠的。
如有任何自然流量增加的問題,或想瞭解關於 SEO 人工智慧解決方案,歡迎立即諮詢,將有 awoo 專業顧問為您服務。



